Graylog 通过 Input 搜集日志,每个 Input 单独配置 Extractors 用来做字段转换。
Graylog 中日志搜索的基本单位是 Stream,每个 Stream 可以有自己单独的 Elastic Index Set,也可以共享一个 Index Set。用 Set 是因为日志的保存会使用一个前缀然后滚动创建新的 Index。Stream 通过配置条件匹配日志,满足条件的日志添加 stream ID 标识字段并保存到对应的 Elastic Index Set 中。同一个 Input 中的日志可以属于不同的 Stream,不同 Input 中的日志可以属于同一个 Stream,就是同一条日志也可以属于多个 Stream。
系统会有一个默认的 Stream,所有日志默认都会保存到这个 Stream 中,除非匹配了某个 Stream,并且这个 Stream 里配置了不保存日志到默认 Stream。
下图是日志处理流程图
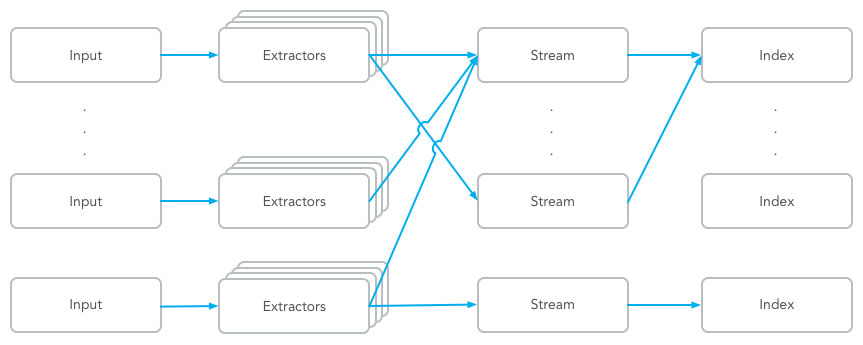
后文会分别分享各个步骤需要注意的一些地方。
Extractor
Extractor 在 System / Input 中配置。Graylog 中很方便的一点就是可以加载一条日志,然后基于这个实际的例子进行配置并能直接看到结果。
内置的 Extractor 基本可以完成各种字段提取和转换的任务,但是也有些限制。在应用里写日志的时候就需要考虑到这些限制。
- 只有字符串类型的字段可以应用 Extractor。比如不能将 Linux Epoch 时间戳通过 Extractor 转成 Elastic 支持的时间格式。
- Extractor 的输入只能是单个字段,输出根据用的方法的不同是可以生成多个字段,比如 JSON 可以解析 JSON 并提取所有字段。
- 字段层级只有一级,也就是日志字段的值不能是复合类型,只能是字符串,数字,时间等。比如使用 JSON Extractor,如果 JSON 中有嵌套的 Object 和 Array 需要选择一种方式展平结构。
Input 可以配置多个 Extractors,按照顺序依次执行。
Stream
Gralog 安装好后会包含一个默认 Stream,可以通过菜单 Streams 创建更多的 Stream。新创建的 Stream 是暂停状态,需要在配置完成后手动启动。
一个 Stream 唯一属于一个 Index Set,但是多个 Streams 可以共享同一个 Index Set。如果共享 Index,那么因为底层 Elastic 的原因会有一个限制: 同一个字段的类型不能一会是字符串,一会是数字,也就是类型必须一致。这个的影响有:
- 在写入日志的时候,如果当前 Elastic Index 中已经存在该字段同时类型不符合,那么冲突的日志会被丢弃,这个错误可以在 System / Overview 中查看。
- 因为上面一条的原因,一个 Index 中某个字段是什么类型取决于该 Index 中第一条含该字段的日志。这样一个 Index Set 中,某个字段的类型可能会不一致,在跨 Index 做数据汇总时会导致出错,比如选择了很长的一个时间跨度。
如果 Graylog 是多个项目共享的话,是很难避免不同项目间字段类型冲突的,所以建议是不相关的日志不要共享 Index Set。这里推荐个人使用的一个策略:
- 为不同的项目创建单独的 Stream 和 Index Set,并且选择不保存到默认 Stream 中。
- 如果需要将某个项目中的一部分日志发往其它服务,比如把错误发到 Sentry,单独创建 Stream 加过滤条件,和该项目的 Stream 共享 Index Set。这个会在下一篇系列文章中提到。
- 如果项目中某些日志很重要,需要有不同的存储策略,或者是需要保存更长时间,那么单独创建 Stream 并使用单独的 Index Set
这样各个项目间不会产生冲突,又能单独配置存储。
Index Set
Index Set 通过菜单 System / Indices 创建。日志存储的性能,可靠性和过期策略都通过 Index Set 来配置。
性能和可靠性就是配置 Elastic Index 的一些参数,主要是
- Shards: 每个 Index 分多少片,每一片可以保存在 Elastic 集群中不同的机器上。日志存储和查询的瓶颈一般是磁盘 IO,通过分片可以将 IO 压力分摊到多台机器。
- Replicas: 每个 Shard 额外保存多少个副本,当有机器出现故障,只要集群内能凑齐每个 Shard 中至少一个副本就不会有任何影响。当然可靠性是靠存储的冗余来实现的,需要消耗更多的磁盘空间。
已经有很多 Elastic 的文章介绍如何进行配置了,就不详细说明。如果集群比较小,不超过3台机器,那么 Shards 可以填 3,而 Replicas 的配置
- 如果没有配置 Elastic 集群填 0
- 如果可以接受集群中节点故障导致部分日志暂时无法搜索到,甚至是永久丢失,或者磁盘比较紧张,填 0
- 如果对可靠性要求高,也有充足的磁盘空间,填 1
过期策略主要根据日志量,磁盘空间,需要查询的时间跨度来决定,Graylog 提供了三种 Index 滚动方案:
- 按时间
- 按 Index 中日志数量
- 按 Index 的占用磁盘大小
通过配置要保留的 Index 数量来删除老的日志。
Pipelines
除了上面提到的日志处理流程,Graylog 还提供了 Pipeline 脚本实现更灵活的日志处理方案。这里不详细阐述,只介绍如果使用 Pipelines 来过滤不需要的日志。
Graylog 中只要日志发到了 Input,常规流程中是没有办法丢弃日志,最终一定会写入到 Elastic 中。有时候可能一些配置错误,比如打开了 DEBUG 级别的日志,导致大量没用的日志占用大量资源。虽然可以单独创建单独的 Stream 和 Index Set 并通过配置过期策略来快速丢弃日志,但日志还是在磁盘上走了一遍。这时就需要 Pipelines 出场了。
下面是丢弃 level > 6 的所有日志的 Pipeline Rule 的例子
rule "discard debug messages"
when
to_long($message.level) > 6
then
drop_message();
end
然后可以创建 Pipeline 关联 Streams 和规则了。
要注意的是,如果 Pipeline Rule 想使用 Extractors 应用之后的字段的话,需要在 System / Configuration 里调整 Message Processors Configuration 的顺序,Pipeline Processor 要放在 Message Filter Chain 后面。